一.Zookeeper
1.架构图
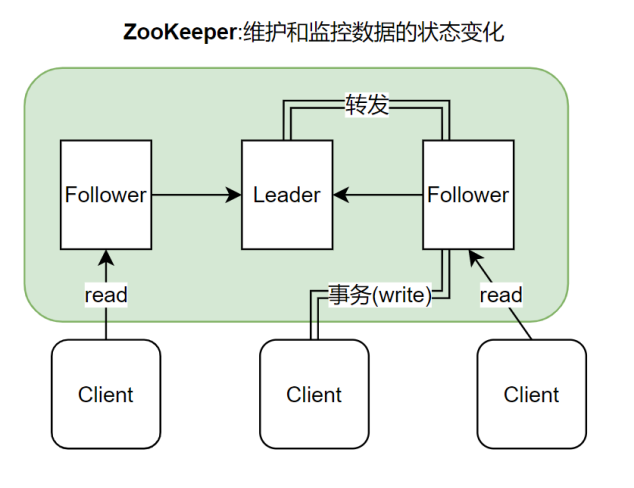
ZooKeeper集群中的机器分为Leader与Follower,其中Leader由机器进行选举产生。Follower接收客户端的读写请求,并将写请求转发至Leader,由Leader再次经过投票,当得到过半应答后将写请求广播至所有Follower,并将结果返回至客户端。
2.主要特点
(1)顺序一致性
同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去。
(2)原子性
所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的
(3)Watch机制
类似于观察者模式。Zookeeper的client监控Zookeeper上的节点,当节点变动时client会收到变动事件提醒
(4)单一系统映像
无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
3.应用场景
(1)配置管理
利用Watch机制,为所有服务器集群的机器注册Watch事件,监控特定保存配置信息的节点,则当需要改变配置信息时仅需要改变对应的节点内容,即可以将更新发布给所有机器,从而触发调用,更新配置信息。
(2)名字服务
Zookeeper维护一个树形文件系统,且对每一个节点的访问都需要通过绝对路径进行访问,每一个节点既有文件的功能,又有目录的功能。由于Zookeeper具有单一系统映像特性,因此能够为访问提供统一的入口。
二.HDFS
1.架构图
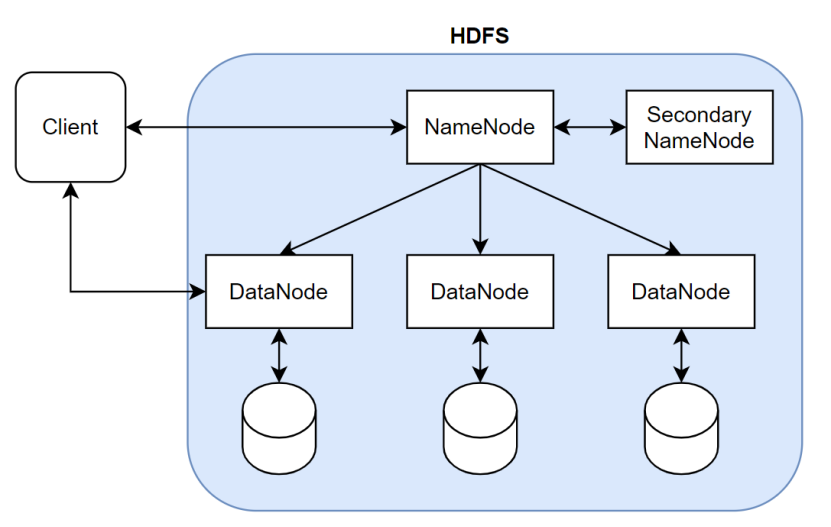
NameNode负责管理文件系统的命名空间,由于文件数目很多的情况下NameNode存储的数据会过大,因此由SecondaryNameNode备份NameNode的部分数据,DataNode存储具体数据。当客户端访问数据时首先访问NameNode获取具体的文件路径,再由DataNode访问数据。
三.MapReduce
1.架构图
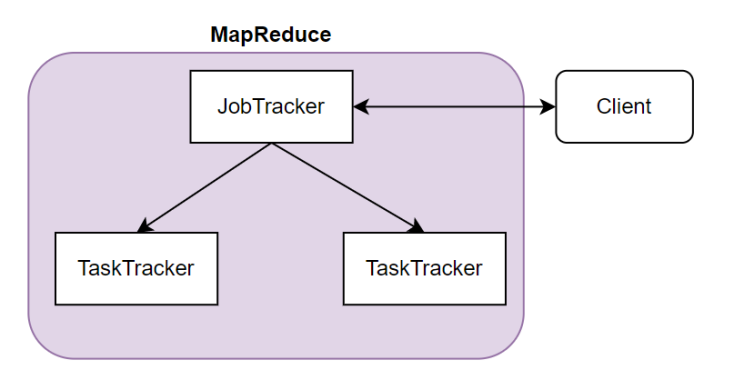
1.在MapReduce1.x版本中,客户端与JobTracker交互,将任务提交至JobTracker,由其分配至各个TaskTracker节点(Map),再将结果整合(Reduce)返回至客户端。
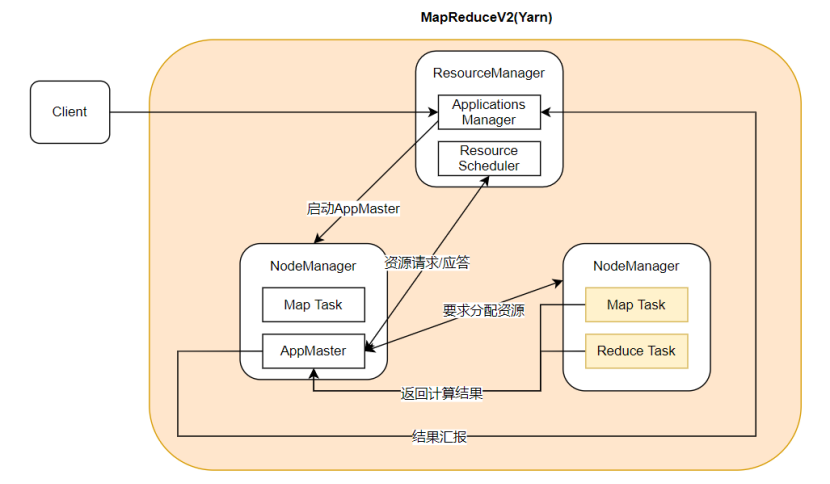
2.在MapReduce2.x版本中引入了Yarn,其中ResourceManager节点类似于JobTracker,NodeManager类似与TaskTracker。客户端首先将任务提交至Applilcations Manager,由其启动某个机器内的AppMaster,AppMaster对Resource Scheduler进行资源请求,利用返回的资源应答通知机器分配计算资源,在被分配的NodeManager中启动Map Task与Reduce Task任务,计算完毕后再将结果返回至AppMaster,由其返回至Applications Manager并提交至客户端。
2.主要特点
(1)易于编程
只要实现MapReduce要求的接口即可完成分布式程序
(2)良好的扩展性
可以简单地增加机器数量来扩展计算能力
(3)高容错性
当一台机器宕机,可以自动将计算任务转移至其他节点进行计算
3.应用场景
MapReduce要求所有输入数据是静态的,且不擅长有向图计算,若需要处理有向图任务,其只能将前面的计算结果存储于磁盘,从而降低性能。因此适用于不需要高实时性的分析型应用场景。
四.Hadoop
1.架构图
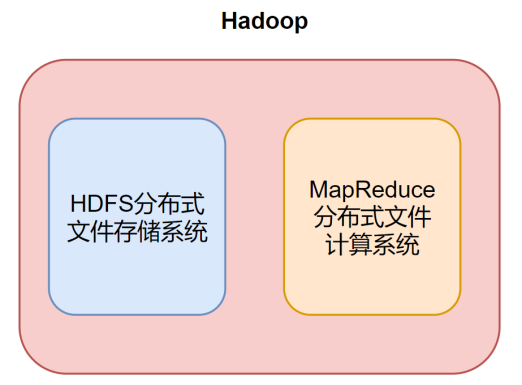
Hadoop利用HDFS作为文件存储系统存储大数据,利用MapReduce作为计算系统执行计算任务
2.适用场景
由于Hadoop采用MapReduce作为计算系统,因此其适用场景也被限制于非实时性场景,适用于分析型计算场景。
五.Hive
1.架构图
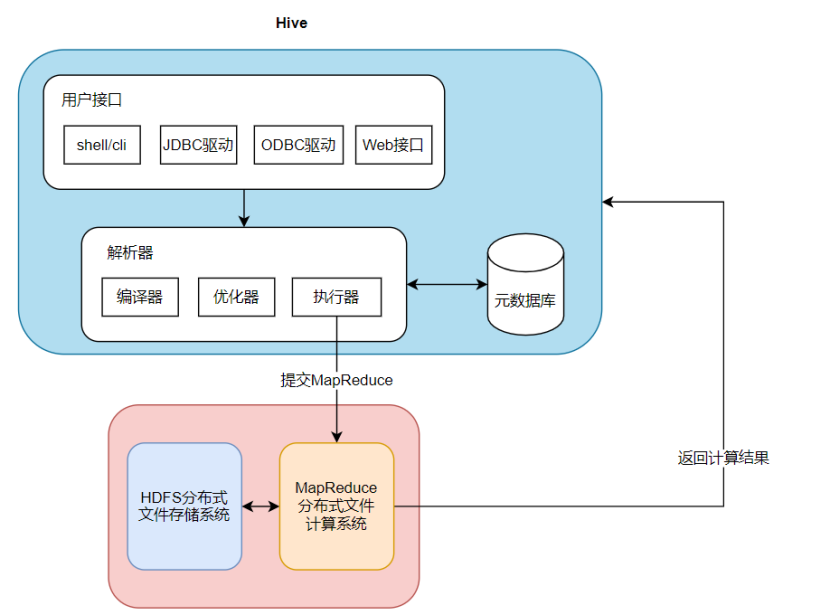
Hive在Hadoop之上封装了一层,将用户输入的SQL语句转化为MapReduce代码,再将转化后的代码发布至MapReduce执行计算任务,因此用于可以不写代码完成计算任务。
2.适用场景
由于Hive将数据转化为MapReduce代码,因此其同样受限于MapReduce特性,仅适用于对实时性要求不高的场景。
六.Spark
1.架构图
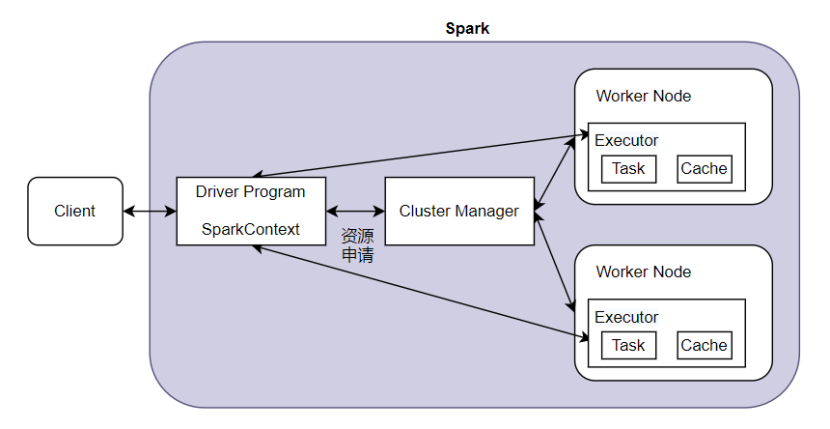
Spark不提供文件系统,仅作为计算系统存在,因此Spark分析大多依赖于Hadoop的HDFS。
首先用户将任务提交至Driver Program,启动SparkContext,SparkContext向Cluster Manager申请Executor资源,Executor向SparkContext申请Task,SparkContext通过分解过程,将应用程序分解为Task发送给Executor执行。
2.主要特点
1.易用性
Spark支持JAVA,Python的API,支持超过80种高级算法,用于不需要编写MapReduce代码,而仅需要通过简短的调用语句就可以实现分布式计算任务
2.通用性
Spark将不同类型的处理提供统一的解决方案,如用户可以在一个应用中使用机器学习与图计算的分布式API
3.速度快
由于Spark可以将计算过程存储在内存中,因此在重复计算时Spark可以调用缓存中的计算结果而不需要重新计算。且Spark在线程启动方面利用fork方式,每一次的MapReduce操作都是基于线程,而Hadoop采用创建新进程的方式,启动一个Task就会启动一次JVM,因此在Task数目多的情况下Spark会比Hadoop节省大量时间
3.适用场景
由于Spark具有极快的计算速度,因此适用于实时场景。

Comment